双map reduce风格 ## 场景 在并行计算中,应想方设法将数据最大化的进行并行处理。如前一步骤处理后的数据不方便进行后续的并行处理,应该转换中间格式。 例如统计一个文件的词频这一场景: 1. 将大文件拆解为多个小文件 2. 小文件在不同的服务器并行处理。在服务器上,按行拆解单词。 3. 统计每一行中,每个单词的词频。并输出到下一步。 4. 输出的格式为 [(hello,1), (world, 2), ... , (hello, 1)] 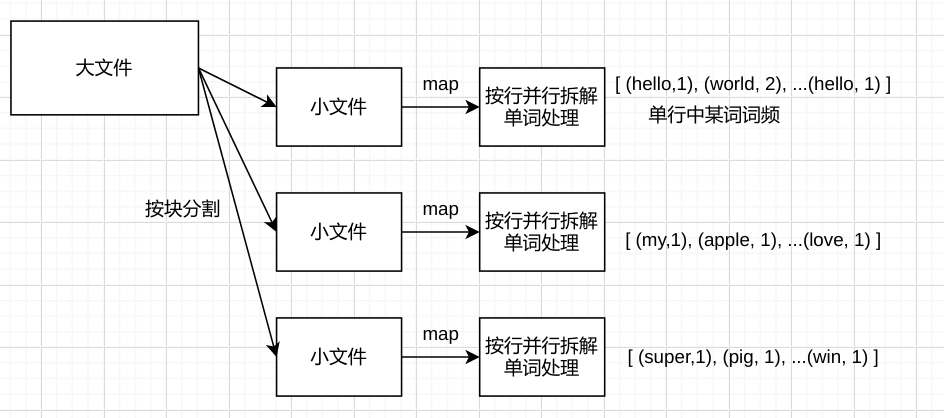 然而,输出的格式并不方便进行下一步并行计算。此时,可以进行regroup操作。将单词以一定规则,统一分类到不同的服务器,进行后续的计算。 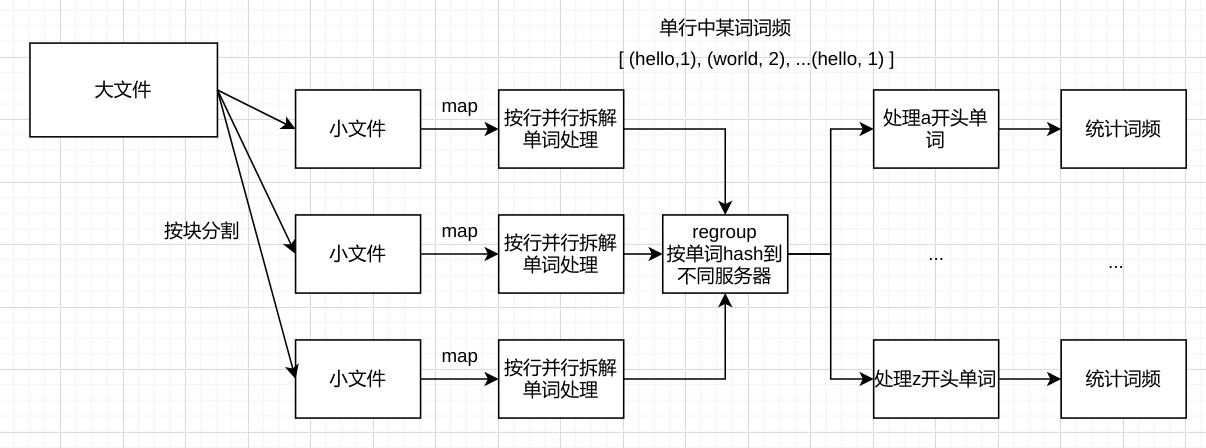 在复杂的场景中,regroup可能需要进行多次。 来自 大脸猪 写于 2021-01-05 19:44 -- 更新于2021-01-05 20:14 -- 0 条评论