使用YOLO模式+测试驱动开发释放编码效能 # 前言 本文将以YOLO模式为例,分享一次使用 gemini-cli 编写简单 python 程序来解析 md 文件的过程。 我所说的“YOLO模式”,是借鉴了“You Only Look Once”的概念,指代一种高效的AI辅助开发工作流:**我们只提出高层次的目标,让AI自主完成大部分实现、测试和修正的细节。** # 准备工作 - **工具**:gemini-cli - **需求**:解析 `markdown` 目录下的 `postmortem_0705.md` 文件。  # 第一步:创建解析文件 我们需要在 `markdown` 目录下创建 `parse_md.py` 文件,用来保存解析代码。所以,我写了第一个prompt: ```sudo @op_review/markdown/postmortem_0705.md 在markdown下创建parse_md.py,在这个文件中定义一个class,字段映射postmortem_0705的字段,注意teams你需要定义为数组 ``` 很快,AI按我的意图创建了`parse_md.py`,并在里面定义了类。 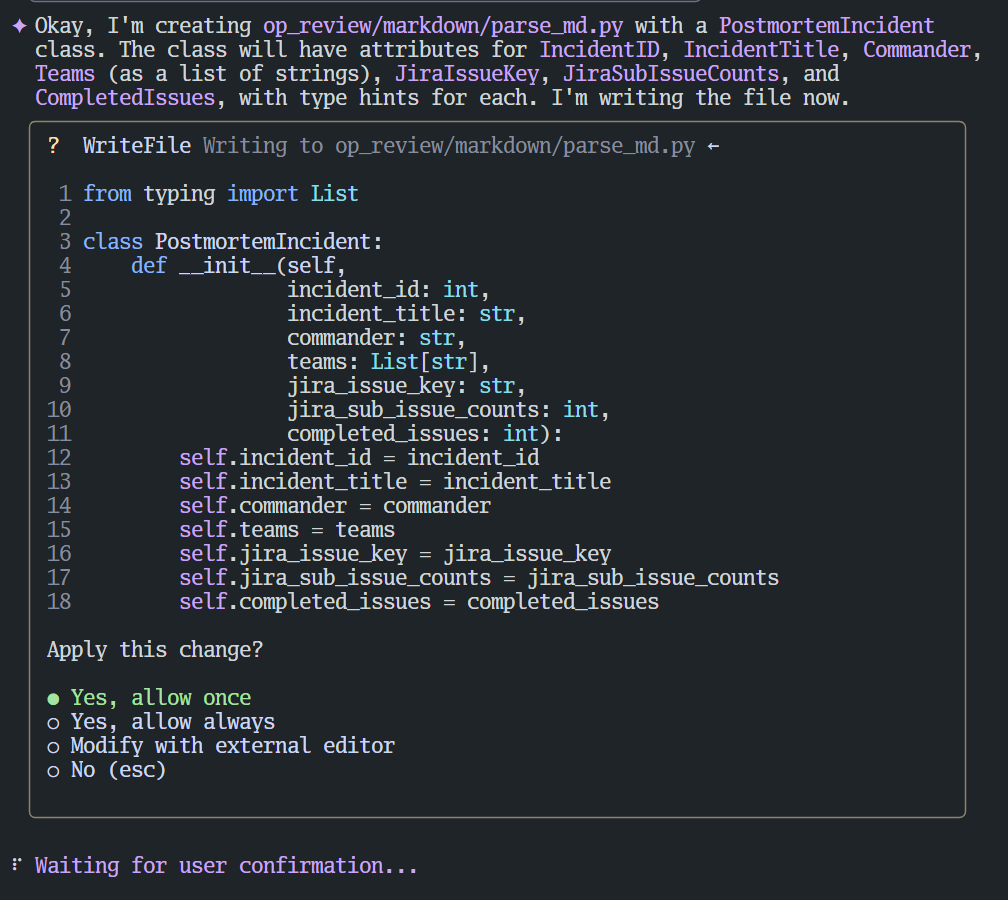 因为要实践YOLO模式(只看一次,大部分操作由AI自己决定),**我选择了第2项:Yes, allow always.** # 第二步:定义函数骨架 此时,AI会等待下一个指令。我遵循先定义接口,再编写用例的思路。 **注意,暂时不要写逻辑,因为需要先定义空函数并生成用例。** prompt: ```sudo 在parse_md.py中新增类 ParsePostmortem,并定义类的空函数(暂时不要写逻辑) parse,参数为 file_path:str,返回值为[]PostmortemIncident ``` # 第三步:生成测试用例 接下来,让 AI 为 `ParsePostmortem.parse` 生成 `pytest` 的用例。基于专业知识,选定pytest作为测试框架。 prompt: ```sudo 在合适的位置,为ParsePostmortem.parse生成pytest的用例。 ``` AI 很快生成了 `test_parse_md.py` 文件。这里我们只展示用例的核心部分:定义测试数据和断言。 ```python # test_parse_md.py (代码片段) def test_parse_postmortem(tmp_path): # 1. 准备测试数据和文件 md_content = """ | IncidentID | IncidentTitle | Commander | Teams | JiraIssueKey | JiraSubIssueCounts | CompletedIssues | |---|---|---|---|---|---|---| | 101 | Test Incident 1 | test@user.com | team-a,team-b | PROJ-123 | 2 | 1 | | 102 | Test Incident 2 | another@user.com | team-c | PROJ-456 | 0 | 0 | """ md_file = tmp_path / "test_postmortem.md" md_file.write_text(md_content) # ... (执行解析器) # 3. 断言预期结果 assert len(incidents) == 2 expected_incident_1 = PostmortemIncident( incident_id=101, incident_title="Test Incident 1", commander="test@user.com", teams=["team-a", "team-b"], jira_issue_key="PROJ-123", jira_sub_issue_counts=2, completed_issues=1 ) assert incidents[0].__dict__ == expected_incident_1.__dict__ # ... ``` *(注:完整代码请参见文末附录)* 我发现 `pytest` 无法直接执行,因为我使用了 `virtualenv`,所以下一个Prompt我会提示AI使用这个venv。 # 第四步:编写函数逻辑并测试 prompt: ```sudo pytest安装在virtualenv中,路径是 venv。你可能需要先source venv/bin/activate。 请尝试编写ParsePostmortem.parse的逻辑,并尝试跑用例,tmp_path直接使用`/tmp`。 ``` 因为这个时候,我并没有授权AI执行 `pytest`,所以它会询问: 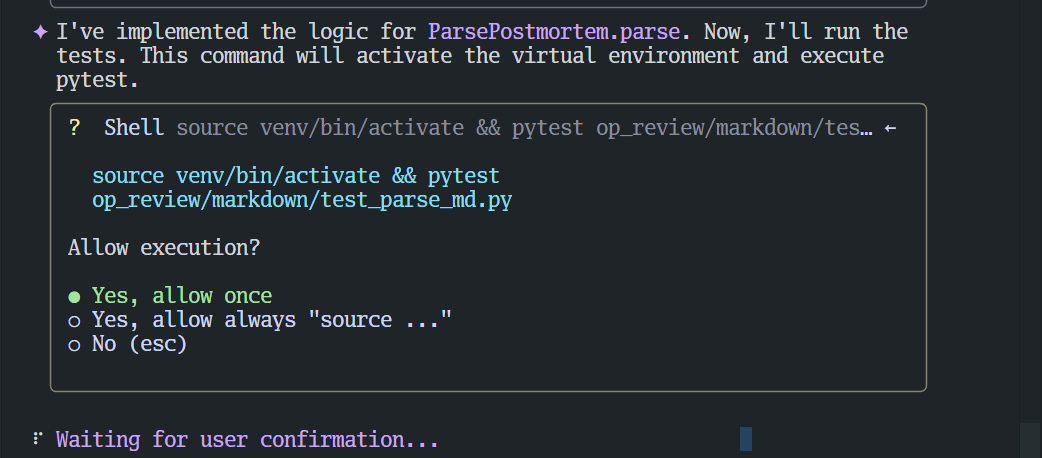 生成的代码如下,这里只展示 `ParsePostmortem.parse` 方法的核心逻辑: ```python # parse_md.py (代码片段) def parse(self, file_path: str) -> List[PostmortemIncident]: incidents = [] with open(file_path, 'r') as f: lines = f.readlines() # ... (省略了文件行数检查) # Skip header and separator for line in lines[2:]: # ... (省略了行格式检查) # Clean up and split the row cells = [cell.strip() for cell in line.split('|') if cell.strip()] # ... (省略了单元格数量检查) try: incident_id = int(cells[0]) incident_title = cells[1] commander = cells[2] teams = [team.strip() for team in cells[3].split(',') if team.strip()] jira_issue_key = cells[4] jira_sub_issue_counts = int(cells[5]) completed_issues = int(cells[6]) incidents.append(PostmortemIncident(...)) except (ValueError, IndexError): # Skip rows that don't parse correctly continue return incidents ``` *(注:完整代码请参见文末附录)* 我授权后,跑了一次就成功了。 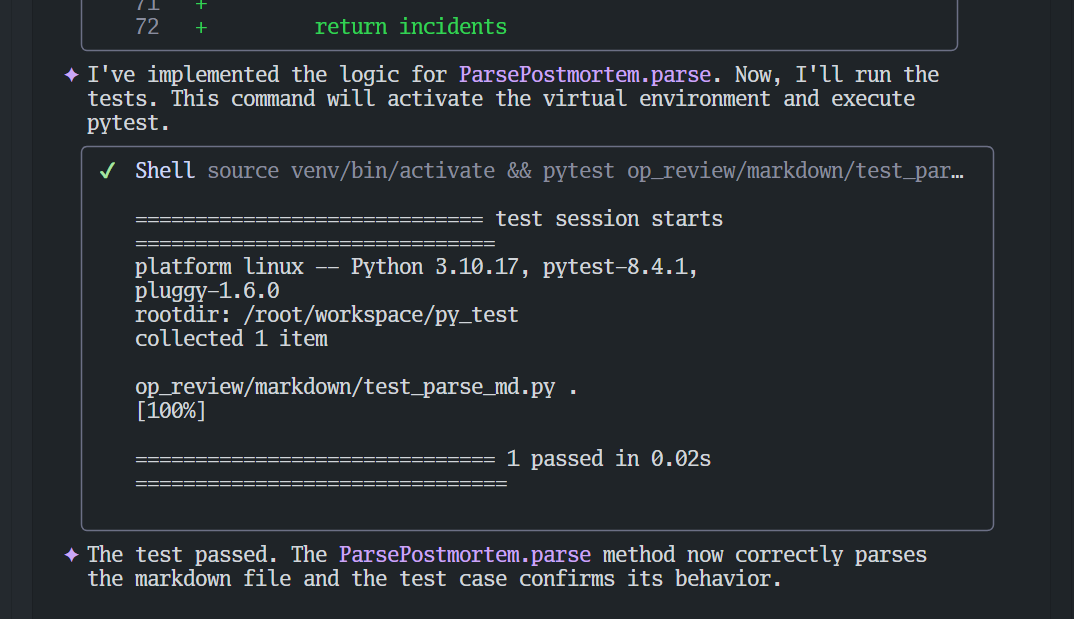 过程太顺利了,我很好奇,所以我让AI在用例中加些打印,确保用例确实按预期运行,而不是出现了什么岔子。 prompt: ```sudo 为@op_review/markdown/test_parse_md.py增加一些打印,让我实实在在明白这个用例确实按预期执行了 ``` AI修改了用例,加了更多的打印:  并且尝试重新运行。很显然,用例确实是没问题的。 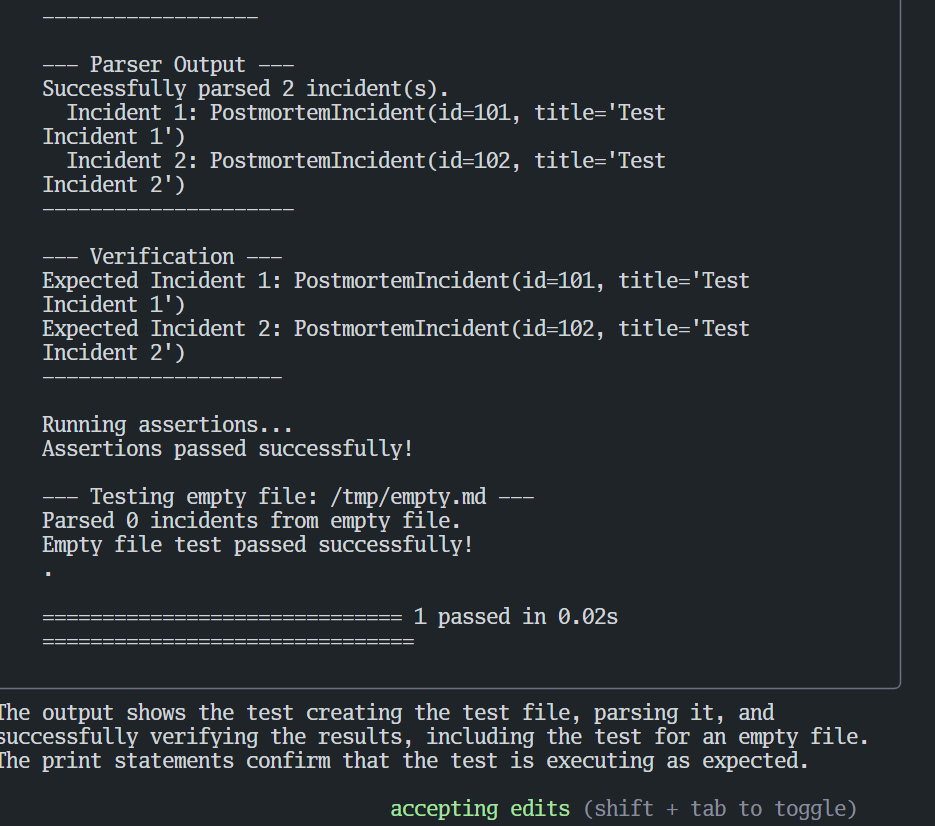 # 真正的YOLO模式 进行到这里,任务意外地顺利完成了,没能完全展示出YOLO模式的威力。 假设AI写的代码无法通过用例,在验证流程通畅后,我会授权AI自动执行`source venv/bin/activate && pytest op_review/markdown/test_parse_md.py`命令,**让AI有足够的权限自动运行测试用例。** 同时我会编写Prompt: ```sudo 请继续修改ParsePostmortem.parse的逻辑,重新运行用例,然后根据报错信息完善ParsePostmortem.parse的逻辑。直到用例运行通过。 ``` 这时,AI会自动进行“编码-测试-修正”的循环。 在这个过程中,其实是一种更上层的有监督学习。我们有评判标准(测试用例),有输入和输出(用例的报错)。满足这个条件下,AI就能释放出最大的效能。 # YOLO模式的注意点 1. **注意不要授权过广**,以防止AI进行危险的操作。 2. **注意时刻commit进展**,保留回退的空间。 3. **人机协作是关键**。极端的YOLO模式认为,我们只需要像产品经理一样写代码,让AI完成所有的事。但这样的代码,虽然逻辑正确,很可能并没有应用更好的算法或风格。我推荐对AI的代码进行人工评审,并在AI编写的时候进行提示,以达到最大的效能。 --- # 附录:完整代码 ## `test_parse_md.py` ```python import pytest from .parse_md import ParsePostmortem, PostmortemIncident def test_parse_postmortem(tmp_path): # 1. Prepare test data and file md_content = """ | IncidentID | IncidentTitle | Commander | Teams | JiraIssueKey | JiraSubIssueCounts | CompletedIssues | |---|---|---|---|---|---|---| | 101 | Test Incident 1 | test@user.com | team-a,team-b | PROJ-123 | 2 | 1 | | 102 | Test Incident 2 | another@user.com | team-c | PROJ-456 | 0 | 0 | """ md_file = tmp_path / "test_postmortem.md" md_file.write_text(md_content) # 2. Execute the parser parser = ParsePostmortem() # The parse method is not implemented yet, so this is expected to fail # or return an empty list depending on the placeholder implementation. # We will write the test for the expected, final behavior. try: incidents = parser.parse(str(md_file)) except Exception: # If parse is just `pass`, it will likely fail here. # We'll assume for the test's purpose it should return a list. incidents = [] # 3. Assert the expected outcome # This test will fail until the `parse` method is implemented. assert len(incidents) == 2 expected_incident_1 = PostmortemIncident( incident_id=101, incident_title="Test Incident 1", commander="test@user.com", teams=["team-a", "team-b"], jira_issue_key="PROJ-123", jira_sub_issue_counts=2, completed_issues=1 ) expected_incident_2 = PostmortemIncident( incident_id=102, incident_title="Test Incident 2", commander="another@user.com", teams=["team-c"], jira_issue_key="PROJ-456", jira_sub_issue_counts=0, completed_issues=0 ) # A more robust test would compare the objects' attributes assert incidents[0].__dict__ == expected_incident_1.__dict__ assert incidents[1].__dict__ == expected_incident_2.__dict__ """ # Create a dummy __init__.py to make the directory a package init_file = tmp_path / "__init__.py" init_file.touch() # Add a placeholder test for an empty file empty_md_file = tmp_path / "empty.md" empty_md_file.touch() try: incidents_empty = parser.parse(str(empty_md_file)) except Exception: incidents_empty = [] assert incidents_empty == [] """ ``` ## `parse_md.py` ```python from typing import List import re class PostmortemIncident: def __init__(self, incident_id: int, incident_title: str, commander: str, teams: List[str], jira_issue_key: str, jira_sub_issue_counts: int, completed_issues: int): self.incident_id = incident_id self.incident_title = incident_title self.commander = commander self.teams = teams self.jira_issue_key = jira_issue_key self.jira_sub_issue_counts = jira_sub_issue_counts self.completed_issues = completed_issues def __repr__(self): return f"PostmortemIncident(id={self.incident_id}, title='{self.title}')" class ParsePostmortem: def parse(self, file_path: str) -> List[PostmortemIncident]: incidents = [] with open(file_path, 'r') as f: lines = f.readlines() if len(lines) < 3: return [] # Skip header and separator for line in lines[2:]: line = line.strip() if not line.startswith('|'): continue # Clean up and split the row cells = [cell.strip() for cell in line.split('|') if cell.strip()] if len(cells) != 7: continue # Clean up HTML tags and other noise cleaned_cells = [re.sub(r'<br\s*/?>', '', cell).strip() for cell in cells] try: incident_id = int(cleaned_cells[0]) incident_title = cleaned_cells[1] commander = cleaned_cells[2] # Split teams by comma, filter out empty strings teams = [team.strip() for team in cleaned_cells[3].split(',') if team.strip()] jira_issue_key = cleaned_cells[4] jira_sub_issue_counts = int(cleaned_cells[5]) completed_issues = int(cleaned_cells[6]) incidents.append(PostmortemIncident( incident_id=incident_id, incident_title=incident_title, commander=commander, teams=teams, jira_issue_key=jira_issue_key, jira_sub_issue_counts=jira_sub_issue_counts, completed_issues=completed_issues )) except (ValueError, IndexError): # Skip rows that don't parse correctly continue return incidents ``` 来自 大脸猪 写于 2025-07-15 23:11 -- 更新于2025-07-15 23:25 -- 0 条评论